
Se ha estudiado el desarrollo de una utilidad que permita llevar a cabo el reconocimiento óptico de caracteres. Su objetivo principal es pre-procesar los ficheros PDF compuestos por imágenes para obtener documentos procesables. Supone una herramienta auxiliar que permita vías futuras que hagan de la Solución RPA un entorno más flexible y adaptativo para facilitar la experiencia de usuario.
Esta herramienta podrá obtener texto de cualquier tipo de imagen, a parte de utilizar ficheros PDFs como entrada, será capaz de reconocer los caracteres que se encuentren en una imagen cualquiera así como de documentos escaneados, impresos o escritos a mano.
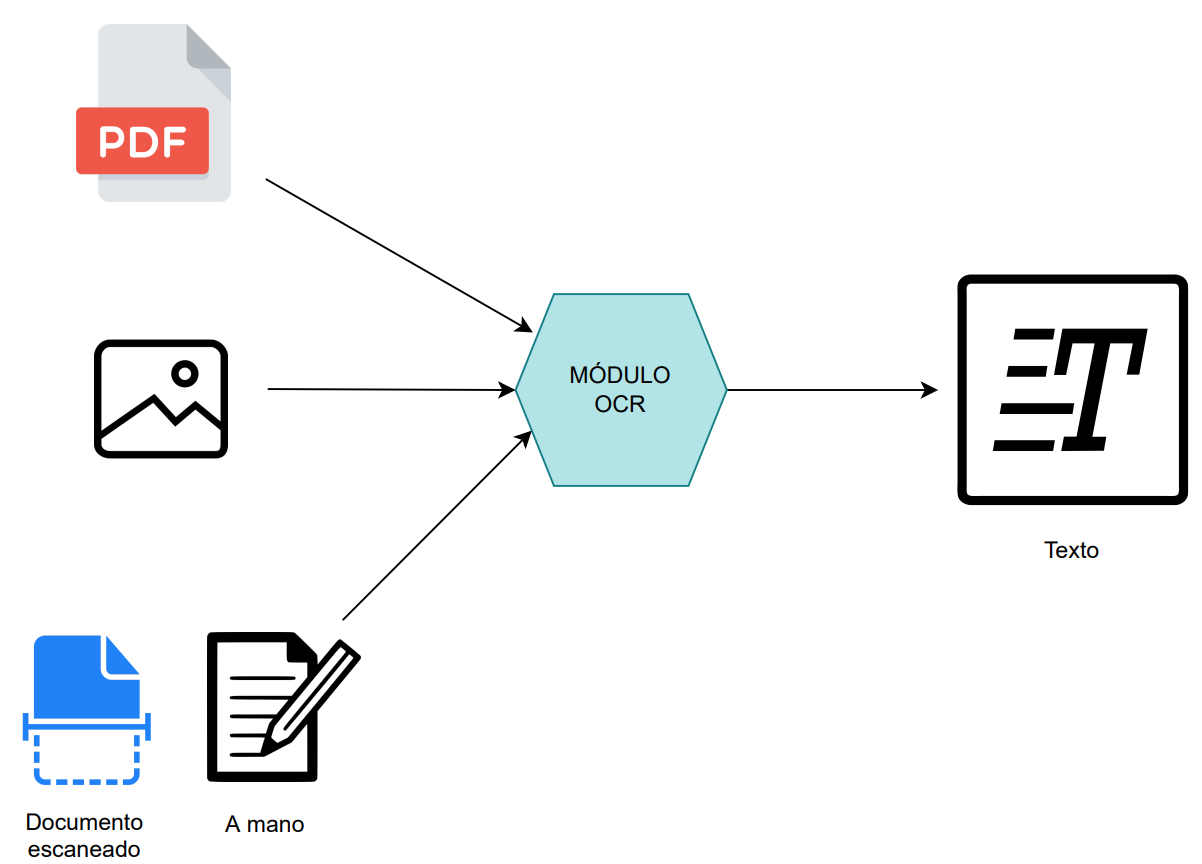
Para poder conseguir este objetivo, se ha seleccionado la librería PyPDFOCR, ya que se trata de una herramienta Open Source de gran potencia y precisión a la hora de llevar a cabo OCRs. Hace uso del motor de reconocimiento óptico Tesseract que se trata de una de las mejores opciones del mercado en cuando a velocidad de procesamiento y precisión en el reconocimiento. Este módulo será un wrapper de estas librerías que adaptará su funcionalidad de forma transparente al usuario para poder procesar documentos desde una interfaz más amigable y sin ser experto en programación o en el uso de estas librerías. A su vez podrá ayudar a cualquier proceso de digitalización que se tenga que llevar a cabo en el proyecto HÉRCULES.